
In der alten Science-Fiction-Welt sprachen die Menschen mit den Geräten, und diese gehorchten aufs Wort. Solche Voice-Bedienung ist heute für einige bereits Alltag. „Licht anschalten“ oder „Radio ausschalten“ oder „Temperatur auf 21 Grad“ verstehen manche Installationen bereits und befolgen brav die Anweisungen. Sowohl Amazon als auch Apple haben Sprachassistenten unters Volk gebracht. Googles Sprachbox kommt bald in Deutschland an.
Die Einsatzszenarien wecken – zumindest bei mir – Skepsis. Sicherlich ist es komfortabel, in einer Ecke der Wohnung zu sitzen und alles per Kommando zu steuern, zumindest die Geräte. Aber ist es wirklich besser? Ich jedenfalls kann mich auch zu den entsprechenden Geräten begeben und sie an- bzw. ausschalten oder die Einstellung vornehmen. Grundsätzlich zwingt ein Sprach-Interface zur Vereinfachung und kann weniger Informationen bereitstellen. Daraus ergeben sich Konsequenzen für die Kommunikation der Menschen und auch für den Handel.
Mit wem kann ich sprechen?
- Amazon vertreibt seine Sprachassistentin Alexa in einem Gerät namens Echo bzw. Echo Dot.
- Apple stattet iPhones, iPads und inzwischen auch die Mac-Computer mit Siri aus, dafür kann auch eine männliche Stimme eingestellt werden.
- Google hat seine Sprach-Interface „Google Now“ bzw. „Google Assistent“ genannt, es steht auf Android-Geräten, und als App für iOS zur Verfügung. Ab Frühjahr 2017 soll auch die Sprachbox „Google Home“ in Deutschland verfügbar sein.
- Microsoft hat die Sprachassistentin Cortana in Windows 10 integriert. Auf Mobilgeräten ist sie allerdings kaum verbreitet und über Pläne zu Einzelgeräten ähnlich Echo oder Google Home ist nichts bekannt.
- Samsung wird auf seinen Handys einen eigenen Sprach-Assistenten namens Bixby integrieren.

Amazons Sprachassistent Alexa steckt in den Echo-Geräten und erfasst die Äußerungen im Raum und führt entsprechende Kommandos aus.
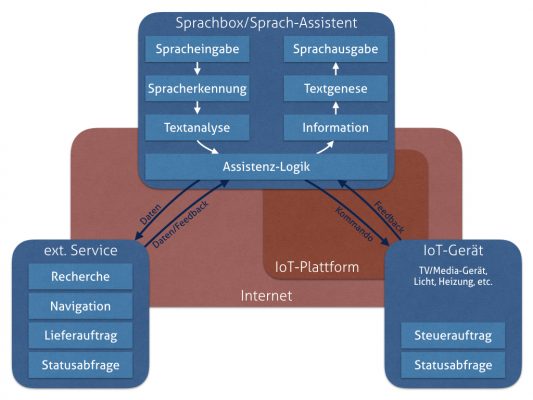
Sprachboxen verarbeiten die Spracheingabe in ihrer Umgebung. Reagieren können sie darauf durch Sprachausgabe. Sie können mit anderen Geräten verbunden sein (Stichwort „Internet of Things“) und beispielsweise Heizung, Küchen- oder andere Geräte steuern. Somit braucht nicht jedes IoT-Gerät ein eigenes Interface mitzubringen, sondern diese Kompetenz wird ausgelagert. Ein Sprach-Interface-Gerät nimmt die Befehle entgegen und übersetzt diese in eine maschinenverständliche Anforderung und überträgt diese an das Zielgerät. Das Zielgerät nutzt den selben Weg rückwärts für Feedback und Informationen an den Nutzer.
Siri und Cortana dagegen sind bereits an ein Gerät gebunden, das Bildschirm sowie Tastatur und Maus oder Touch-Bedienung mitbringt. Somit dienen diese Sprachassistenten primär zur Steuerung des Smartphones (ist ja auch ein Computer), Tablets oder Laptop/PC. Diese wiederum können über die Sprachsteuerung dann IoT-Geräte steuern. Sowohl Apple als auch Google haben dazu eine Protokoll-Plattform für die Verbindung von IoT-Geräten integriert. Mit Siri kann ich auch Apple-TV steuern und dadurch meinen Fernseher. Das gilt analog auch für Google Now und Chromecast.
Diktat, Kommando und Anweisung
Es gibt letztlich drei Einsatzszenarien:
- Es wird eine Texteingabe diktiert. Aus den gesprochenen Lauten wird eine lesbare Abfolge von Worten. Das ist nicht so trivial, wie es klingt. Diktierprogramme hatten vor zehn Jahren noch arge Probleme mit normaler Sprache und den oft fehlenden Pausen zwischen den Worten.
- Ein Kommando wird per Sprache gegeben, d.h. die Spracherkennung erkennt den enthaltenen Befehl und lässt diesen ausführen. „Kommando“ bezeichnet klare, lineare Anweisungen oder Befehle, wie „Licht an“, „Radio lauter“, „Waschmaschine starten“, „Wecker auf neun Uhr stellen“, „an Termin mit Thomas am Freitag 18 Uhr erinnern“, „die gleiche Pizza wie vor drei Tagen bestellen“. Linear bedeutet, dass zur Ausführung keine weiteren Entscheidungen anfallen, sondern diese direkt ausgeführt werden können. Eine weitere Interaktion ist bei einem Sprachkommando nicht nötig. Meist erfolgt ein Feedback in Form einer Erfolgs- oder Scheitermeldung oder durch die wahrnehmbare Ausführung (das Licht ist an).
- Per Sprache wird eine Anweisung gegeben, die Folge-Aktionen (Plural) und/oder -Entscheidungen auslösen. Diese können entweder ebenfalls per Sprache erfolgen oder auch mit Bildschirm-Unterstützung; dabei würden beispielsweise mehrere Optionen angezeigt werden, aus denen der Nutzer wählt. Dazu gehören auch Such- oder Recherche-Aufträge. In einfachen Fällen („Wann wurde Darwin geboren?“) erhält man sofort das Ergebnis. In komplizierteren Fällen („Wie ist das Geheimrezept von Coca-Cola?“) dagegen wird nicht das Rezept ausgegeben, sondern eine Auswahl von Quellen, worin man etwas über dieses Geheimrezept erfährt – der Nutzer wählt dann selbst aus, ob und was er davon liest.
Ob der Nutzer „nur“ diktiert, ist durch den Nutzungskontext meist klar. Dafür wird Diktierbereitschaft durch das Gerät signalisiert, oder das Diktat ist in ein Kommando eingebettet: „Schreib Thomas eine Nachricht: Komme später, melde mich noch mal.“ Kommandos und Anweisungen setzen nach dem Diktat an. Durch ein Auslösesignal beginnen Alexa, Google Now oder Siri mit der Sprachaufnahme und -erkennung. Anschließend wird der erkannte Text analysiert, ob er Kommandos oder Anweisungen enthält, und diese werden dann ausgeführt.

Siri erweitert seine Kompetenzen beständig.
Der freundliche Computer
Was Sprachsteuerung so angenehm macht, ist eben ihre Sprache. Der Nutzer verwendet die gleiche Kommunikationsform wie auch sonst in seinem Alltag; dazu ist kein separates Gerät, wie eine Tastatur oder Maus, zu bedienen. In jeder Situation, in der man sprechen kann, ist es damit möglich, auch dem Sprachassistenten etwas zu sagen. In jeder Situation, in der man hören kann, ist es damit möglich, auch eine Sprachausgabe zu verstehen.
Die in den vergangenen Jahren enorm gestiegene Qualität der Spracherkennung und Sprachausgabe trägt dazu bei, dass wenig Bedienfrust entsteht.
Die tatsächliche Magie liegt jedoch in der Assistenz-Logik. Nur verstandene Sprache ergibt lediglich ein Diktat, und nur vorgetragene Angaben ergeben lediglich eine (kurze) Vorlesung. Damit die Interaktion als sinnhaft erlebt wird, braucht es einen spürbaren Mehrwert zwischen Sprachein- und -ausgabe. Diesen schafft die Assistenz-Logik, indem sie aus dem erkannten Text Kommandos, Anweisungen interpretiert, deren Ausführung auslöst und das Feedback in verständlicher Weise ausgibt. Erst in der Kombination dieser Einzelteile – Spracheingabe, Sprachausgabe, Ausführung (selbst oder durch angesprochene externe Services oder Geräte) und Feedback – entsteht ein Sprachassistent.
Zwischen Spracheingabe und -ausgabe schafft die Assistenz-Logik den Mehrwert für ein Voice-Interface.
Nebenwirkungen neuer Technologien
Deren Einsatzspektrum ist noch beschränkt, aber Gadget-Enthusiasten und Early Adopter sind begeistert. Doch jede Technologie hat kulturelle Auswirkungen. Als der Buchdruck erfunden wurde, lernten mehr Menschen lesen und schreiben. Immer mehr Schulen wurden benötigt, Wissen war kein elitärer Vorteil mehr, sondern stand vielen zur Verfügung. Dabei entdeckten viele Menschen, dass sie Sehfehler haben – so entstand ein Markt für Brillen, die heute auch als modisches Accessoire dienen. Vorlesen und Geschichten erzählen wurde etwas für Kinder, Erwachsene zogen sich mit ihrer Lektüre zurück und lasen still für sich. Immer stärker galt als bedeutend, was man wusste – denn das Wissen war für viele verfügbar. Erkenntnissuche fand zwischen den Seiten und weniger in der Welt statt, das Bildungsbürgertum entstand. Außerdem stieg der Lichtbedarf, und zahlreiche Häuser brannten durch Kerzen oder Gas- oder Öllampen ab.
Jedes Jahr werden allein in Deutschland über 90.000 neue Bücher veröffentlicht, darunter auch welche von Hera Lind und unzählige Kochbücher; doch wer will die alle lesen und nachkochen, wer trennt noch die Spreu vom Weizen? Gutenberg wäre überrascht, was seine Erfindung alles direkt und indirekt bewirkt hat. Und hätten die Käufer der vergleichsweise günstigen Gutenberg-Bibel geahnt, welcher Technologie sie durch ihren Geldfluss den Weg ebnen und welche kulturellen und sozialen Entwicklungen daraus erwachsen, vielleicht hätten sie zögerlicher zugegriffen?
Bildtelefonie klang beispielsweise nach einer grandiosen Idee. Doch hat sie sich nicht durchgesetzt. In einigen Bereichen ist sie sinnvoll und wird geschätzt; dazu zählen Telefonkonferenzen, die mit Bildübertragung oft effektiver ablaufen, oder persönliche Gesprächen mit Personen, die weit entfernt sind und die man lange nicht gesehen hat. Doch in Gesprächen unterwegs oder nebenbei – und diese machen die Mehrzahl der Telefonate aus – ist Bildtelefonie nicht gewünscht. Übrigens bestand eine der relevanten Geschäftsideen bei der Erfindung des Radios, Musik zu übertragen. Für die Musikaufzeichnungen via Phonograph bestand der erwartete Einsatzzweck, dass sich die Menschen Audio-Botschaften senden und damit die Postkarten ablösen. Die Annahmen in der Anfangszeit einer neuen Technologie fallen oft recht verquer aus, jedenfalls im Rückblick.
Voice-Interfaces simulieren soziale Situationen
Doch hier liegt der Unterschied: Voice-Interfaces sind zwar eine neue Technologie, aber sie werden nicht als Technologie erlebt, sondern als soziale Simulation, indem sie auf verbaler Kommunikation basieren. Statt eben den Alltag noch technischer zu machen, entfernen sie scheinbar Technologie, da mir die Bedienung von Geräteknöpfen erspart bleibt – ein Kommando genügt.
Statt eine Person zu bitten, das Radio anzuschalten, das Fenster zu schließen oder an das Licht-Auschalten zu erinnern, kann ich dies mit dem gleichen Aufwand einfach selbst tun. Der schöne Vorteil dabei ist, dass so ein Sprach-Assistent immer höflich bleibt und die Aufträge erledigt, mit ihm muss ich nichts diskutieren. Insofern fühlt es sich tatsächlich so an, als hätte ich einen unsichtbaren persönlichen Diener, der mir lästige Kleinarbeiten abnimmt, für die ich sonst andere Tätigkeiten unterbrechen müsste und die eigentlich unter meiner Würde sind. Dieses Herrschaftsgefühl unterstützt vor allem den Wunsch aller Nutzer nach Kontrolle über ihre Umgebung – vielleicht ist „Kontrolle“ auch nur der Euphemismus dafür, dass sich jeder irgendjemandem überlegen fühlen möchte.
Dafür bietet sich ein Sprach-Interface an, denn es kennt keine Gefühle, simuliert aber eine kommunikative Situation. Durch die Sprachein- und -ausgabe wird der Computer vermenschlicht, ohne zu menschlich zu werden, er wirkt wie der wohlwollende Geist, der einem nur helfen will. Die Reduzierung auf akustische Interaktion verringert eine zu intensive Bindung oder emotionale Interpretation der Situation. Etwas schizophren haben wir also einen willfährigen Geist, der uns aufs Wort gehorcht, der aber nicht zu menschlich wirkt, sodass wir uns keine moralischen Fragen über unsere Kommandokultur stellen.
Wem nutzen Sprach-Interfaces?
Als Unterstützung für eingeschränkte Personen ist die Stimmbedienung auf jeden Fall eine unschätzbare Erleichterung im Alltag. Das setzt allerdings eine moderne Wohnung mit angemessener Schalldämmung voraus, sonst schallen die „Licht an“-, „Radio aus“-, „Wecken um neun“-Kommandos auch zu den Nachbarn. Im Gegensatz zu den Augen sind die Ohren nicht verschließbar. Wer also in der gleichen Wohnung lebt, wird kaum umhin kommen, jedes Voice-Kommando zu hören. Hoffentlich besteht dann Einigkeit über das Ziel, sonst eskalieren Situationen schnell:
„Licht an.“
„Licht aus.“
„Licht an!“
„Licht aus!“
„Das ist mir zu hell! Licht aus!“
„Und mir ist es zu dunkel! Licht an!!“
Der Mensch ist ein bequemes Tier. Er wird nur aufstehen, zum Lichtschalter gehen und an- bzw. ausschalten, wenn es ihm notwendig erscheint. Das ist kein großer Aufwand. Aber noch unaufwändiger ist es, gar nicht erst aufzustehen, sondern einfach nur den Wunsch als Kommando zu äußern. Wenn außerdem das Medium, das sonst für die Verhandlung und Kompromissvereinbarung genutzt wird, nun gleichermaßen zur Umsetzung des eigenen Wunsches dient – warum dann den Zusatzaufwand der Verhandlung überhaupt auf sich nehmen?
Der Korridor des Akzeptablen und Tolerierten schrumpft so weiter, schließlich ist der eigene Optimalzustand nur ein Stimmkommando entfernt. Das lässt das Ertragen eines nicht als optimal empfundenen Zustands zur Qual werden. Der so entstehende Frust gilt natürlich weder den Geräten noch sich selbst, sondern der unverschämten Person, die einen anderen Optimalzustand anzustreben sich erdreistet.
Insofern wird das Zusammenleben nicht unbedingt erleichtert, fordert und fördert aber die soziale Kompetenz.
Lineare Aufgaben, wenn keine Hand frei ist
Ein sinnvolles Einsatzgebiet sind klare lineare Aufgaben, wie „Wecken um neun“, „Termin mit Sabine am Freitagabend“ oder „Thomas anrufen“. Es gibt tatsächlich Situationen, in denen es effektiver ist, eine solch klare Anweisung zu sprechen, als die entsprechende Aktion (Wecker stellen, Termin eintragen oder Telefonnummer wählen) selbst auszuführen. Ein verständliches Einsatzgebiet ist das Auto, denn schließlich soll der Fahrer seine Hände am Lenkrad lassen und kann so dennoch verschiedene Aufgaben nebenbei erledigen, indem er seinen Sprachassistenten kommandiert.
Beliebt ist das Szenario einer Person, die beide Hände nicht frei hat, aber dringend etwas erledigen muss, eben beispielsweise das Radio anschalten oder Seite 43 im Kochbuch aufschlagen, obwohl sie nicht vom Herd weg kann. Ja, solche Fälle gibt es, aber stellen sie einen wirklich relevanten Mehrwert dar? Brauche ich dafür wirklich ein neues Gerät, das mir diese „Arbeit“ abnimmt? Bis sich Kaufpreis, Installation und Wartung amortisieren – von dem gelegentlichen Stress des Nicht-Funktionierens abgesehen –, werde ich jahrzehntelang das Radio auf herkömmliche Weise anschalten können.
Ja, ich bin ein Bequemlichkeitsskeptiker und beargwöhne Automatismen. Selbst wenn ich wohlwollend das Szenario durchspiele, dass eine junge Mutter mit dem Baby auf dem Arm dank einer Sprachbox in ihrer Wohnung Dinge beauftragen könnte, für die sie sonst keine Hände frei hätte, so bin ich immer noch nicht von der Notwendigkeit überzeugt.
Über plausible und mehrwert-stiftende Gebiete wie Autofahren oder Baby-im-Arm wird eine Technologie in den Alltag gelassen, die ihrerseits wieder Rückwirkungen auf die Menschen und deren Zusammenleben haben. Natürlich wird niemand es einer Mutter neiden, dass sie sich mit beiden Händen um ihr Baby kümmern und trotzdem nebenbei andere Dinge erledigen kann. Oder dass beim morgendlichen Aus-der-Wohung-Stürmen sowohl Wetterbericht nebenbei erfahren und alle Lampen korrekt ausgeschaltet werden. Menschheitsträume werden wahr!
Kurzes Innehalten: Sind das wirklich Probleme? Verdienen diese Situationen wirklich das Wort „Problem“, oder sind sie nicht eher Symptome einer Lebensführung, die nun durch Voice-Interfaces besser erträglich werden? Aber solche lebensphilosophischen Fragen beantwortet jeder für sich selbst, und jeder für sich selbst wird entdecken, dass es hin und wieder Situationen gibt, in denen die Sprachbedienung etwas erleichtert. Und weil es so gut geklappt hat, wird es dann zunehmend öfter genutzt, und irgendwann kann man sich gar nicht mehr daran erinnern, wie man früher ohne diese Unterstützung klarkam.
Die Geschäftsmodelle hinter der Sprache
Wir stehen am Anfang dieser Technologie im Alltag. Im Gegensatz zum Buchdruck handelt es sich um web-basierte Dienste, die mächtigen Unternehmen (Amazon, Google, Apple, Microsoft und bald Samsung) gehören. Diese Unternehmen sind Aktionären – und damit der monetären Wertsteigerung – verpflichtet. Natürlich möchten sie uns die Nutzung ihrer Sprach-Assistenten versüßen und so einfach wie möglich machen. Doch nicht, um unser Leben tatsächlich langfristig zu vereinfachen, sondern um damit Geld zu verdienen.
Wer sich also für den Einsatz eines Sprachassistenten begeistern kann, sollte das dahinter stehende Geschäftsmodell prüfen:
- Apple: Benutzer-Bequemlichkeit, um die Kunden an die eigene Hardware-Plattform (iPhone, iPad, Mac, Apple-TV) zu binden. Die Integration in das Auto („CarPlay“) und in die Apple-Watch erweitern die Einsatzgebiete von Apple-Technologie und die Nutzung ihrer Dienste.
- Google: Anzeigen verkaufen. Die Hardware-Einnahmen und andere Geschäftsfelder sind nicht annähernd so lukrativ für das Unternehmen wie das Geschäft mit Anzeigen. Damit werden die Nutzer zum Produkt gegenüber den Anzeigen- oder anderen Kunden.
- Amazon: Bestellungen generieren. Mit Prime und Kindle hat der Handelsriese eine Infrastruktur geschaffen, um den Kunden das Bestellen von Produkten so einfach wie möglich zu machen und dadurch die Bestellmenge kontinuierlich gesteigert. Die Sprachbox und deren einfache Integration in den Alltag sind ein weiterer Bestellkanal – je selbstverständlicher diese sind, desto selbstverständlicher wird das Bestellen.
- Microsoft: Der Zyniker in mir behauptet, Cortana existiert nur, weil Microsoft beweisen will/muss, dass es auch Sprachassistenz kann. Ein Geschäftsmodell dahinter habe ich noch nicht entdeckt.
- Samsung: Abhängigkeit von Google reduzieren und Bindung der Kunden an die eigene Geräte-Plattform erhöhen. Da Samsung alle Geräteklassen bedient, könnte das sehr effektiv sein, denn Samsung-Waschmaschinen, -Kühlschränke, -Fernseher, -Kameras etc. können langfristig so alle reibungslos miteinander über Bixby agieren.
Technologie und wirtschaftliche Interessen lassen sich nur in einer realitätsfremden Verzerrung voneinander getrennt denken. Damit ist jede Technologie immer den Macht- und politischen Strukturen unterworfen. Und wenn es einer Technologie gelingt, im Alltag der Menschen anzukommen und darin integriert zu werden, entsteht eine Abhängigkeit oder gar eine Abhängigkeitsverflechtung. Abhängigkeit ist das Gegenteil von Freiheit, die ja angeblich ein so hohe Gut ist. Und gern geben die Menschen wieder voller Ignoranz ein Stück Freiheit her, wenn ihr Leben dafür auch nur ein bisschen bequemer wird. „Bequem“ ist hier abfällig gemeint und beinhaltet auch, dass das eigene (vermeintliche) Wohlergehen über andere (fremde) Interessen gestellt wird.
Von dem Wortkommando „Licht an“ zu „Licht aus“ für die Freiheit sind es nur wenige Gedankensprünge.
Suchen via Stimmeingabe
Bei Suchanfragen werden drei Intentionen unterschieden:
- informationales Interesse: Fakten, Hintergründe, Content
- navigationales Interesse: Überblick erhalten, Optionen erfahren
- transaktionales Interesse: etwas tatsächlich tun, z.B. kaufen/bestellen oder beauftragen
Legt man die gleichen Intentionen für die Sprachsuche zugrunde, so zeigt sich rasch das Dilemma. Einen Fakt wie „Wann wurde Bismarck geboren“ oder „Wann läuft der Film XY im Kino YZ“ kann die Maschine recherchieren und kurz und bündig ausgeben. Das tut Google bereits in seiner „Fact Box“, die bei vielen Suchanfragen angezeigt wird. Hintergründe oder anderen Text-Content wird man sich jedoch kaum von der Maschine vortragen lassen: „Wie kam es zum dreißigjährigen Krieg“, „Warum beging van Gogh Selbstmord“ oder „Wie bestehe ich die Fahrprüfung?“
Zum einen ist die Quellenlage oft nicht so eindeutig, ich will ja nicht nur die Wikipedia-Version hören. Zum anderen habe ich es beim Zuhören schwer, einen Text auf Relevanz abzuscannen oder eine kurze Gedankenpause einzulegen. Aber das Störendste an maschinenvorgelesenen Texten ist deren Monotonie, die Maschine weiß ja nicht, wann eine dramatische Pause, ein stimmliches Augenzwinkern oder andere Variationen nötig sind, um die Zuhörer bei Laune zu halten (für Interessierte hier eine digitale Vorlesung dieses Textes als MP3, 12 MB, 50 Minuten).
Ähnliche Herausforderungen stellen sich bei navigationalen Anfragen. „In welchem Kino läuft Film XY“ mag noch sinnvoll sein, aber lange Listen mit verschiedenen Parametern werden rasch anstrengend. Oft interessiert nicht nur der Kino-Name, sondern auch die Spielzeit oder ob heute Kinotag ist oder in welcher Sprachfassung der Film gezeigt wird. Dies alles immer gleich vorzutragen, wäre zu viel des Guten. Der Nutzer muss sich also selber bemühen und diese Abfragen separat stellen. Auf einem Bildschirm wären diese Infos alle auf einen Blick dargestellt und die Entscheidung rasch getroffen.
Gleiches gilt für die transaktionalen Intentionen. Bei Alexa ist schon mal klar, dass ich bei Amazon bestellen will. Aber bei einem Sprach-Interface ist Komplexitätsreduktion nötig, sodass mir voraussichtlich entgeht, dass ein Produkt von verschiedenen Anbietern bei Amazon eingestellt wurde, vielleicht genügt mir auch ein gebrauchtes Exemplar, das günstiger ist.
So wie Aufträge möglichst kurz, eindeutig und vor allem linear (also options- oder zwischenentscheidungsfrei) sein sollten, werden auch Suchanfragen nur dann akzeptable Ergebnisse liefern, wenn sie entsprechend präzise und fokussiert gestellt werden. Ein System, das auf Sprachein- und -ausgabe basiert, verlangt also auch dem Nutzer Komplexitätsreduktion ab. Wichtige Nebenklänge oder -aspekte werden uns so vorenthalten. Ich erfahre also auch nur das, was ich wissen will. Kollateralinformationen erhalte ich so nicht.
Aus diesen Überlegungen heraus ergeben sich drei Problemfelder: Vollständige Kommandos, Händler werden überflüssig und Voice braucht Hilfe.
Ich kann nur beauftragen, was ich kenne
Voice Kommandos sind vor allem dann sinnvoll, wenn ich sie vollständig geben kann und mir ihre Ausführbarkeit bekannt ist. Ich muss vorher bereits genau wissen, was ich will: eine kleine Aufgabe erledigt, einen Fakt erfahren, ein konkretes Produkt bestellen o.ä. Durch die Linearität der Sprachaus- und -eingabe entspricht die Voice-Bedienung wieder der Kommandozeile unter MS-DOS. Diese Linearität ist zwar einerseits sehr mächtig, aber andererseits auch sehr limitierend – und zwar sind der Nutzer und dessen Kenntnis das Limit.
Das erinnert an die Textparser der Text-Adventure-Spiele der 1980er Jahre, wo Befehle wie „Bring the wood to the lake“ als „Pick up stick <Enter> Go north <Enter>“ einzugeben waren. Nur wenn der Nutzer die korrekten Befehle kannte, wurden sie korrekt verstanden und ausgeführt. Die Voice-Software ist zwar intelligenter und fehlertoleranter geworden, aber Kontexte, Ironie oder andere natürliche Sprachgewohnheiten bereiten ihr weiterhin Probleme. Immerhin wird die Frage „Kannst du mir sagen, wie spät es ist“ nicht wörtlich genommen (und mit „Ja“ beantwortet), sondern Siri antwortet: „Es ist 21:35 Uhr, Alexander. Guten Abend.“ Außerdem sollte man sich nicht verhaspeln, mitten im Satz neu ansetzen oder ähnliche Sprachunsauberkeiten pflegen – je kürzer der Befehl, desto höher die Chance, dass er verstanden werden kann.
Für einfache Wissensabfragen „Wer ist der aktuelle Präsident der USA“ oder „Wie lautet das Rezept für Coca Cola“ ist eine Voice-Bedienung effektiv und zielführend. Allerdings verrät mir Siri das Coca-Cola-Rezept nicht, sondern verweist auf diverse Internetseiten, die behaupten, dazu etwas zu wissen. In diesem Fall ist die bekannte Faktenlage ebenso ein limitierender Faktor. Auch hier ist Siri wieder im Vorteil, weil es einfach mehrere Online-Quellen auf dem Bildschirm auflisten kann, die zu meiner Anfrage passen (indem aus meiner Frage eine Websuche generiert wird). Siri behandelt den Großteil der informationalen Anfragen (inklusive jener nach dem aktuellen US-Präsidenten) also wie navigationale Anfragen und liefert als Ergebnis eine Reihe – meist – passender Webseiten, aus denen ich mir eine aussuchen und lesen kann. Doch was tun Alexa und Google Now in dieser Situation?

T-Shirt: Grumpy Cat als Trump
Jede Sprachbedienung, die rein linear erfolgt und ohne Bildschirm auskommen muss, unterliegt der Tendenz, das Gleiche, das Bekannte zu liefern. Würde durch diverse Umstände das Meme im Internet kursieren, dass „Grumpy Cat“ US-Präsident wäre, und würde es diese Info sogar in Wikipedia schaffen, dann wäre Googles Antwort auf die Frage, wer aktueller US-Präsident sei, mit „Grumpy Cat“ algorithmisch richtig, aber inhaltlicher Blödsinn. Da würde es auch nicht helfen, wenn wir die Frage, wieder und wieder wiederholen, die Antwort bleibt „Grumpy Cat“.
In jedem menschlichen Dialog wäre spätestens bei der Nachfrage klar, dass die gegebene Antwort inhaltlich nicht passt, da auch Tonfall und Körpersprache mindestens Skepsis ausdrücken. Doch diese Feinheiten kennt die Sprachbox (noch) nicht und muss daher scheitern. Eine Maschine kann in absehbarer Zeit den Unterschied zwischen einer plausiblen Fehlinformation und einer richtigen Information nicht erkennen.
Für die Mensch-Maschine-Interaktion besteht immer das Dilemma, beide Verständniswelten miteinander in Einklang zu bringen. Was ich nicht genau benennen kann, kann ich dem Gerät nicht mitteilen. So wird es schnell bequemer, einfach immer wieder das selbe Essen beim gleichen Lieferanten, die gleichen Kleidungsstücke und die gleiche Musik zu ordern. Zu groß ist das Risiko eines „Überrasch mich“. Inspiration, Abweichung, Neues hat so eine schlechtere Chance. Eine Produktempfehlungsseite wie Amazon sie anbietet (und mir somit die eine oder andere Anregung liefert), ist via Sprache kaum akzeptabel. Der Aufwand, sich das alles anzuhören steht in keinem Verhältnis zum Nutzen, eine solche Empfehlungsmenge einfach abzuscannen.
Ich lande in der Echokammer meines eigenen Komforts, und mein Kühlschrank bestellt immer den selben Käse.
Tod des Handels

Google Home hört wie Amazons Echo in den Raum und reagiert auf Sprachkommandos.
Dass Alexa die Spracheingabe „Playstation bestellen“ als Lieferauftrag interpretiert, liegt in der Logik des Sprach-Assistenten. Siri, Bixby, Cortana und Google Now würden diese Eingabe als Recherche-Anfrage oder Navigationsauftrag verstehen und Kaufmöglichkeiten für eine Playstation anbieten. In einem Folgeschritt könnte dann – zumindest theoretisch – auch der Auftrag ausgelöst werden. Eine solche Entwicklung ist vor allem bei Google Now zu erwarten, denn diesem Dienst liegen bereits alle nötigen Informationen vor.
Spinnt man den Gedanken weiter, gelangt man zu einem Voice-Zeitalter, in dem Zwischenhändler kaum noch eine Chance haben. Wozu braucht es Lieferheld, wenn ich die Pizza über Alexa, Siri oder Google Now bestellen kann? Für die Pizzerien ist es attraktiver, sich direkt bei diesen anzumelden. Google hat die meisten Informationen ja eh schon. Ja, das ist noch Zukunftsmusik, aber lange dürfte es nicht mehr dauern. Wieso soll ich einem Voice-Interface schließlich auftragen: „Bestelle Pizza Salami über Lieferheld bei Maier Pizza“?
Zwischenhändler braucht keiner mehr
Insofern haben Lieferando und Kollegen (Hotel-, Autokauf- und andere Vermittlerseiten wie Check24) im Voice-Zeitalter nur noch eine Berechtigung als Brückentechnologie, um kleinen Anbietern den Erstkontakt mit der Voice-Plattform zu erleichtern. Was ist derzeit der Vorteil, bei Lieferando zu bestellen? Ein Gutschein via Newsletter und eine gleichförmige und gleichwertige Darstellung des Speisenangebots, sodass mir das Auswählen erleichtert wird, und beim Bestellen stehen mir unabhängig vom gewählten Lieferanten die gleichen Zahlungsoptionen zur Verfügung. Das könnte Google ebenso. Über die Präsentation und Gutscheine hinaus generieren Vermittlerseiten keinen echten Mehrwert für Kunden, denn Amazon, Google und Apple haben eigene Bezahlsysteme und können Bestellungen selbst verarbeiten bzw. direkt an den Lieferanten senden.
Abstrakt gesehen tun Vermittlerseiten nichts anderes, als die Daten zahlreicher Anbieter zusammenzutragen und mir zu präsentieren, sodass ich eine Auswahl treffen kann. Für mich entsteht der Mehrwert, dass ich nicht selbst recherchieren muss, sondern an einer Stelle alle Angebote zusammengefasst und vergleichbar präsentiert bekomme. Für die Anbieter entsteht der Mehrwert dadurch, dass weitere Zielgruppen erschlossen werden.
Moment mal, das Gleiche tut Google doch auch für Internetseiten. Ohne Google hätte ich deutlich weniger Leser, insofern schafft es mir als Blog-Anbieter einen Mehrwert. Und für die Leser entsteht der Mehrwert dadurch, dass sie nicht alle Blog-Seiten der Welt kennen und durchforsten müssen, sondern einfach Google fragen. Und wenn das für Inhalte so gut funktioniert, dann doch sicher auch für Waren und Dienstleistungen. Das würde es den Nutzern noch leichter machen, denn egal, was sie brauchen: Google kann es besorgen.
Foodora hat dagegen einen zusätzlichen Mehrwert zu den anderen Vermittlern: Es ermöglicht dank seines Lieferdienstes auch in Restaurants zu bestellen, die keinen eigenen Lieferservice haben. Vorstellbar ist aber, dass sich künftig die Aufgabe auch genau darauf beschränkt, bestelltes Essen auszuliefern, während die Bestellung über Google oder Siri oder Alexa abgewickelt wird.
Bestellen via Sprache
Das gilt auch für alle anderen Arten von Händlern. Bei Alexa ist klar, dass diese nur Bestellungen für Amazon annimmt. Aber Siri und Google Now ist es ebenfalls egal, woher ein Produkt geliefert wird, ob aus dem Lager eines Fabrikanten oder aus einer Ladenfiliale. Im Zweifelsfall entscheidet eh der Preis oder der Lieferkomfort.
Wie oft wird man das Gerät beauftragen „Bestelle das blaue Olymp-Hemd in der Größe 41 bei Trikotagen-Heinz, Querfeldstraße“? Hand aufs Herz: Mir ist es meist egal, wer mir das Hemd liefert, sofern es das richtige ist, die Lieferung rasch erfolgt und ich keinen zusätzlichen Stress habe. Der Absendername auf dem Paket ist mir da schnuppe. Die Händler und Händler-Marken werden dadurch zu Handelsnetzen degradiert.
Das heißt nicht, dass die Voice-Search das allein bewirkt. Sie befördert nur einen Trend, der im eCommerce bereits üblich ist: Bestellt wird dort, wo es am billigsten ist und am wenigsten Stress macht. Amazon punktet da vor allem bei Komfort und Stressarmut (= Zuverlässigkeit, Prime-Zustellung). Dafür nehmen viele auch in Kauf, dass es nicht immer das absolut billigste Angebot bei Amazon ist, aber die Preise dort sind zumindest immer dem billigsten nahe.
Kaufen bei Google
Andersherum gefragt: Wann bestellen Menschen eigentlich nicht bei Amazon? Wenn sie es noch billiger möchten oder Vorbehalte gegen den Riesen haben. Letztere werden eh keine Alexa oder Echo Dot in ihre Wohnung lassen, erstere würden kaum ein Sprach-Interface nutzen, denn die Preis- und Angebotsrecherche ist auf einem Bildschirm viel effektiver als via Sprachein- und -ausgabe.
Obwohl, wenn Google auf die Frage „Was ist das günstigste Angebot einer Playstation“ korrekt antwortet und den Folge-Auftrag „Bestell dort eine Playstation“ wunschgemäß ausführt, würden vermutlich auch die preissensitiven Kunden zur Sprachsteuerung wechseln. Damit entscheiden künftig nicht mehr sie selbst, wo sie bestellen, sondern de facto Google – und damit wird seine Macht noch größer.
Vermutlich wird sich Google solche prominenten Voice-Platzierungen sogar noch besser vergüten lassen als seine bisherigen Shopping-Anzeigen. Schließlich haben bei den Bildschirm-Anzeigen mehrere Anbieter eine Chance, angezeigt zu werden – der Nutzer entscheidet dann, welchen er wählt. Aber in der komplexitätsreduzirten Voice-Welt gäbe es keine „erste Google-Seite“ mehr, sondern nur noch den Kampf um Platz 1.
Microsoft Cortana ist wie Siri an Mobilgeräte und Computer gebunden.
Bei Siri und Cortana sind solche Kauf-Integrations-Optionen bislang nicht absehbar. Allenfalls iTunes-Inhalte sind derzeit direkt durch Siri steuerbar, sodass die Anweisung „Playstation kaufen“ immer den iTunes-Store öffnet. Ich gehe davon aus, dass diese Fälle in Zukunft besser behandelt werden – auch wenn es nicht zum Geschäftsmodell von Apple gehört, so muss auch für solche Fälle das Sprach-Interface-Angebot als sinnvoll erlebt werden, um nicht das Voice-Interface-Erlebnis zu diskreditieren.
Unsichtbare Händler
Der Zeitschriften- und Buchhandel basiert bereits auf einem unsichtbaren Händlernetz (Grosso genannt), ebenso der Apothekenmarkt mit den pharmazeutischen Großhändlern. Den meisten ist egal, wie der konkrete Laden oder die Ladenkette heißt, es zählt nur der passende Zeitschriftentitel. Ob ich „Spiegel“, „c’t“ oder „Eulenspiegel“ im Bahnhofskiosk, in der Zeitschriftenabteilung einer Buchhandlung oder in einem Supermarkt kaufe, ist letztlich unerheblich, sondern es zählt die Bequemlichkeit für mich: Ich kaufe sie dort, wo ich gerade bin, sodass ich die geringstmögliche Verzögerung zwischen Kauf-Intention und -Erfüllung habe (aufgrund der Preisbindung entfällt glücklicherweise der Recherche-Aufwand). Gleiches gilt für Bücher, auch wenn dort die Anbieterdichte niedriger ist als bei Zeitschriften, oder für Medikamente, ein Aspirin ist ein Aspirin, egal wo ich es kaufe oder bestelle.
Gesetzlich dürfen zwar Großhändler (Grossisten) nicht an Endverbraucher verkaufen, aber deren Handelsnetz und deren Regeln für die Geschäfte bestimmen bereits unser Einkaufserlebnis und die Auswahl. Die Geschäfte sind quasi die Schaufenster und Verkaufspunkte für deren Angebote – so wie Google in der Bildschirm- oder Voice-Version gleichfalls nur noch der letzte Kontaktpunkt in der Handelskette zum Kunden hin ist. Das Grosso-Netzwerk agiert für die Kunden unsichtbar und besitzt keinerlei Kaufentscheidungsbeeinflussungspotenzial, kaum jemanden kümmert es, an welchen Großhandel ein Geschäft angeschlossen ist.
Eine solche Verschiebung im Handel ergibt sich nicht über Nacht. Aber was für Zeitschriften, Bücher und Medikamente funktioniert, ist auf die meisten Sortimente problemlos übertragbar. Dann nehmen Google oder Alexa die Rolle des Geschäftes ein – und den meisten Kunden dürfte es egal sein, von welchem Händler das Produkt dann tatsächlich geliefert wird. Auch das ist Komplexitätsreduktion: Den Kauf von Waren auf das Wichtigste zu beschränken, nämlich Produkt, Preis und Lieferung. Der Händler, der sonst zwischen Hersteller und Kunde steht, wird durch Google ersetzt.
Auf einer Voice-Plattform als Nicht-Amazon oder als nicht-günstigster Anbieter bestehen zu wollen, wird zur großen Herausforderung für den Handel.
Sichtbare Händler
Ketten wie „C & A“, „h & m“ oder „Ernstings Family“, die ihr eigenes Sortiment führen, das es eben nur dort gibt, sind auch künftig auf Ladengeschäfte angewiesen. Wie diese Marken auf die Voice-Plattformen gelangen, ist die spannende Frage. Ebenso spannend ist die Folgefrage: Werden Kunden tatsächlich ein „rotes T-Shirt von h & m“ oder „ein rotes T-Shirt unter zehn Euro“ als Kommando aufgeben?
Für diese Handelsketten wird der Online-Anteil womöglich sogar wieder sinken, denn auf den Voice-Plattformen funktionieren sie nur bedingt. Damit bleiben ihnen Apps und eigene Online-Shops, die aber bei der unterstellten Verbreitung von Voice-Interfaces an Bedeutung verlieren. Außerdem können sie ihr Angebot in einem Voice-Interface schlecht präsentieren, denn Modehandel basiert vor allem auf Kauflust und Inspiration, wenn nicht gerade ein pragmatischer Nachkauf ansteht.
In der Zuspitzung ergibt sich eine ziemlich scharfe Trennung zwischen inspirierendem, beratenden Offline-Handel und pragmatischem voice-getriebenem Online-Handel.
- Zielkäufe, wenn ich genau weiß, was ich will, erfolgen via Voice.
- Die Recherche nach Details erfolgt via Voice. Die Recherche, welche Produkte für mein Ziel geeignet sind, kann via Voice oder im visuellen Internet erfolgen.
- Stöbern findet im visuellen Internet und in Offline-Geschäften statt.
- Anlasskäufe (eine Mischung zwischen Stöbern und Zielkauf), wenn man ungefähr weiß, was man benötigt (z.B. ein Geburtstagsgeschenk für Tante Frieda bis 50 Euro, sommerliche Kleidung für den Sommer oder eine unterhaltsame Komödie für den Feierabend), erfolgen offline oder visuell. Voice wird nur genutzt, wenn bereits konkrete Anhaltspunkte vorliegen und als Anweisung formuliert werden können, beispielsweise: „Eine dekorative Keramikvase für 40 bis 50 Euro“, „grüne Shorts in Größe XL und zwei weiße T-Shirts in XL“ oder „Filme mit Jennifer Aniston“ – aber auch das würde man meist eher zumindest mit visueller Unterstützung erledigen. Oder man stöbert gleich gezielt durch ein Geschäft.
Da das visuelle Internet dank Voice-Interfaces an Bedeutung für Kaufvorgänge verliert und die App-Nutzung ebenfalls zurückgehen wird, bleiben als große Handels-Hoffnung der Offline-Handel und eine – noch zu erfindende – sinnvolle Integration in das Sprachbedienungsmodell. In der Kaufvorbereitungsphase dagegen wird Voice eine weniger starke Rolle spielen. Damit ergibt sich eine Kluft:
- Kaufvorgang: Wenn man weiß, was man will, steigt die Tendenz, es via Voice zu bestellen, wo der Händler nachrangig ist.
- Kaufvorbereitung: Wenn man noch nicht genau weiß, was man will, wird man dies seltener mit einem Voice-Interface recherchieren.
Wer also potenzielle Kunden von einem Produkt überzeugt, muss sich darauf einstellen, dass der Kauf dann via Voice erfolgt – also vermutlich bei jemand anderem. Die kostenaufwändige Warenpräsentation (im Geschäft oder Online-Shop) und der Kauf (via Voice) finden auf zwei verschiedenen Kanälen statt. Und in mindestens einem ist der Händler immer benachteiligt. Wer sehr gut darin ist, seine Produkte günstig und effektiv auch über Voice-Interfaces anzubieten (sie also in den Voice-Plattformen zu integrieren), wird die Inspirationskunden vernachlässigen. Wer sehr gut darin ist, seine Produkte zu präsentieren und bei Kunden Interesse zu wecken, wird die gezielten Voice-Bestellungen verpassen.
Für dieses Dilemma gibt es keinen erkennbaren Ausweg, außer die Hoffnung, dass Voice-Interfaces nicht so dominant werden, wie ich es hier unterstelle. Aber: „Hoffnung ist des Kaufmanns Tod.“ Nicht ohne guten Grund erweitert selbst der größte Online-Händler der Welt sein Filialnetz: Warum Filialen für Onlinehändler so wichtig sind.
Pizza bestellen via Voice
Spielen wir noch einen profanen alltäglichen Bestellfall durch, der die grundsätzliche Voice-Problematik gut illustriert.
„Pizza bestellen.“
„Die gleiche wie vor drei Tagen?“
„Nein. Pizza Salami.“
„Folgende Lieferdienste führen Pizza Salami: Maiers Pizza, vier Komma drei Sterne. Mindestbestellwert zwölf Euro. Pizza Salami sieben Euro neunzig. Pizza Lehmann, drei Komma neun Sterne. Kein Mindestbestellwert. Pizza Salami acht Euro vierzig. Pizza Italia, vier Komma sechs Sterne. Mindestbestellwert fünfzehn Euro. Pizza Salami acht Euro siebzig.“
Aus einem scheinbar einfachen Sprach-Kommando wird in der Praxis schnell eine Anweisung. Das Dilemma sind Aufgaben, die eben nicht linear und klar sind, auch wenn sie zunächst so scheinen. Selbst das Pizza-Bestellen ist keine triviale Angelegenheit, sondern umfasst viele Teilentscheidungen, aus denen dann die eigentliche Entscheidung abgeleitet wird. Was die Maschine eben nicht weiß – es sei denn, sie trägt auch eine erkleckliche Menge der Kundenmeinungen vor –, ist, dass Maiers Pizza einer anständigen Tiefkühlpizza entspricht, Pizza Lehmann zwar rasend schnell liefert, aber mitunter die Bestellungen verwechselt, und die Pizzen oft labberig sind, und dass Pizza Italia zwar recht lange für die Lieferung benötigt, die Pizza aber knusprig und lecker ist. Außerdem hat Pizza Lehmann gerade eine Aktionspizza „Salami Fungi“ für sieben Euro im Angebot.
Der Mensch kann nun diese Informationen gegeneinander wichten und mit seiner aktuellen Interessenlage abgleichen: erwartete Essensqualität, benötigte Liefergeschwindigkeit, zu zahlender Preis – ergänzend kommen häufig noch ein subjektiver Wunsch nach Abwechslung, Neugier oder Abenteuerlust hinzu. Die Maschine kann dem Menschen die Entscheidung nicht abnehmen, aber in einer Sprach-Interface-Welt kann sie auch nicht alle verfügbaren Optionen verlesen. Drei Lösungsansätze bieten sich an:
- Die Maschine liest einfach alles vor. Bis sie damit fertig ist, habe ich entweder keinen Hunger mehr, bin weggedöst oder kann mich an die Details nicht mehr erinnern. — Dieser Ansatz ist somit nicht praxistauglich.
- Die Sprachmaschine kann ein Bildschirmgerät ansteuern, dort die verfügbaren Angebote anzeigen, und der Kunde ordert dann per Spracheingabe: „Bestell bei dem dritten der Liste, und bestell Pizzabrötchen dazu.“ — Dieser Ansatz ist nicht „voice-only“, sondern setzt weitere Technologie und Bedienschritte voraus.
- Die Maschine reduziert die Auswahl auf zwei Optionen: Anhand diverser Parameter oder historischer Daten werden die wahrscheinlichste Option vorgeschlagen und als Alternative „andere Pizza-Angebote“. So hat der Nutzer immer noch die Wahl, ob er die Empfehlung annimmt (was er in den meisten Fällen tun wird), aber die Liste der anderen Angebote ist für ihn ebenfalls gut erreichbar. — Der Ansatz passt zum Anspruch an einen Assistenten, aber die Alternativen-Auswahl läuft in das gleiche Dilemma: entweder nicht voice-tauglich oder Zusatztechnik nötig.
Siri ist hier im Vorteil, denn es steckt immer in einem Gerät mit Bildschirm. Werden darauf die Informationen bzw. Optionen übersichtlich angezeigt, ist die Entscheidung rasch getroffen. Alexa wiederum hat den Vorteil, dass der Lieferant immer klar ist: Amazon (oder ein an dessen Marktplatz angeschlossener Händler). Insofern wäre nur noch das konkrete Produktmodell zum Bestellen herauszufinden. Da Amazon ja erste Experimente mit Lebensmittellieferung betreibt, ist es wohl auch nicht mehr weit zur Lieferung von zubereiteten Speisen.
Stimm-Bedienung benötigt Displays
Allein aus Effizienzgründen funktioniert eine Stimmbedienung nur gut, wenn sie auch eine Bildschirmansicht steuern kann. Diktiere ich eine dreizeilige Nachricht, bin ich schneller beim Korrektur-Überfliegen, wenn ich sie auf einem Bildschirm sehe, als wenn mir das Gerät sie noch einmal vorliest. Muss ich zwischen mehreren Optionen wählen, ist es besser, diese optisch darzustellen als vorzulesen. Ebenso sind die drei oben skizzierten Pizzalieferanten besser tabellarisch vergleichbar als in der gefühlt endlosen Vorlesung. Bei Navigationsgeräten haben wir uns daran gewöhnt, dass die Stimmausgabe mit einer Kartenansicht verbunden ist, sodass wir den Kontext der Anweisung einordnen können.
Der Verzicht auf den Bildschirm erfordert, wie bereits angerissen, eine Komplexitätsreduktion. Wenn Google zu einer Suchanfrage derzeit meist eine Fülle von Seiten vorschlägt, mir also bei der Entscheidungsfindung hilft, muss ich bei der Sprachsteuerung entweder den Modus wechseln (von Sprache auf Bildschirm) oder mich vermutlich mit dem ersten Ergebnis begnügen. Damit entfällt für viele Webseiten – wie auch diesen Blog – ein Großteil des Publikums. Selbst für große Verlagswebseiten wäre es dann enorm schwierig, im Internet eine Leserschaft aufzubauen.
So wie jetzt SEO ein wichtiges Kriterium für Webseiten ist und Mobile-Readiness vorausgesetzt wird, so kommt künftig die Voice-Readiness hinzu. Der Anteil des Traffics von Mobilgeräten macht bereits mehr als 50 Prozent aller Seitenaufrufe aus – wer seine Webseite nicht auf diese Geräte optimiert, verpasst also mindestens die Hälfte des potenziellen Publikums. Innerhalb von zehn Jahren hat sich das mobile Internet von einer „nice to have“-Angelegenheit zur Pflicht entwickelt. Diese Entwicklung hat bereits eine Komplexitätsreduktion bewirkt, denn auf einem Handy-Bildschirm passt nun einmal nicht so viel wie auf einen Laptop- oder PC-Monitor.
Etabliert sich die Nutzung von Sprachgeräten wie „Google Home“ oder „Amazon Echo“, wird ein Teil des Traffics über diese Kanäle kommen. Ob solche Sprachgeräte potenziell zu einer „Voice only“-Nutzung führen, ist bislang nur spekulativ. Falls sich das Internet tatsächlich von einem Ansichtsmedium zu einem Steuer- und Sprachmedium entwickelt, müssen zahlreiche Wirtschaftsbereiche umdenken.
Verrät Science Fiction die Zukunft?

In „Star Trek IV“ scheitert Scottie an der Bedienung, denn die Maus reagiert nicht auf Spracheingabe.
Vielleicht gibt ja tatsächlich die Science Fiction einen realistischen Ausblick. In „Star Trek“ erfüllt ein sehr kompetenter Sprachcomputer sämtliche Anforderungen und Aufträge. Jedoch werden Informationen in Text- und Bildform immer noch auf Bildschirmen angezeigt; die anzuzeigenden Inhalte werden aber nicht mehr manuell gesucht, sondern per Sprache angefordert.
Somit wird „Voice only“ vielleicht wirklich nur eine Randerscheinung zur Gerätesteuerung, während Bildschirme weiterhin als Hauptinteraktionsfläche dienen. Dann wäre das Verständnis der Sprachboxen nicht als neue Version des Internet, sondern als Zwischenstation, bevor jedes Gerät seine eigene Sprachsteuerung mitbringt. So wie die omnipräsente „Mother“ in „Alien“ oder der omnipräsente „Computer“ in „Star Trek“ überall erreichbar sind und so alle Winkel der jeweiligen Raumschiffe kommunikativ miteinander verbinden.
Wenn wir abschätzen wollen, wann Sprachsteuerung wirklich alltagstauglich ist, orientieren wir uns daran, wie Menschen mit ihrem Geld umgehen. Wenn die ersten Hausfrauen oder Beamten ihre Bankgeschäfte via Siri, Alexa, Google Now oder Cortana erledigen, ist die Sprachsteuerung im Mainstream angekommen, und die umwälzende Interface-Revolution ist Realität.
IoT als Hürde zu reibungsloser Voice-Realität
In den Prognosen des „Internet of Things“ (der allumfassend vernetzten Geräte) werden zahlreiche Aspekte vernachlässigt oder kleingeredet. Diese betreffen auch die Sprachsteuerung und alle damit verbundenen Geräte:
- Sicherheit: Zahlreiche Geräte sind unsicher, leicht zu hacken und somit manipulierbar (schönes Beispiel: die unsichere Netzwerkverbindung eines Vibrators)
- Usability: Die Vernetzung gestaltet sich nicht nur technisch herausfordernd, sondern auch in der Bedienung. Wenn Google Now etwas anzeigen möchte, könnte es vielleicht den Fernseher nutzen; dazu sollte es allerdings jedes Mal um Erlaubnis fragen, um sich nicht den Zorn der übrigen Wohnungsbelegschaft zuzuziehen. Dank Chromecast wäre die Anbindung an den Fernseher sogar innerhalb des Google-Universums möglich.
- Standardisierung: Zahlreiche konkurrierende Standards erschweren die Verbindung der Geräte. Entweder beschränkt man sich auf die Produkte eines Herstellers (hoffentlich pflegt der sein Sortiment auch gut und für mich passend) oder wählt einen übergreifenden Standard, der jedoch – das haben Standards so an sich – bestimmte Sonderfunktionen eben nicht kann.
- Obsoleszenz: Alle Geräte müssen aktuell gehalten werden (ob durch Software- oder Hardware-Update), um korrektes Funktionieren miteinander zu gewährleisten. Das bedeutet im schlimmsten Fall alle fünf Jahre einen Komplettwechsel.
- Investition: Gute und verlässliche Technik kostet Geld. Die Menschen wollen aber billig. Daher wird es immer eine Kluft zwischen Erwartung/Anspruch und Realität geben.
Ein Sprachsteuerungsproblem sind außerdem Kontext, Missverständnisse und Fehlinterpretationen, die zu unerwünschten Ergebnissen führen. Dass ein Tonkommando aus dem Fernseher und nicht von mir kommt, dass ein fremdsprachlicher Name oder Titel fehlerkannt wird oder der Sinn eines Auftrags falsch verstanden wird, kann direkt unerwartete Auswirkungen oder auch langfristige Konsequenzen haben. (Aktuelles Beispiel: eine Burger-King-Kampagne nutzte Voice-Geräte für ihre über Wikipedia gepflegte Marketingbotschaft – zu blöd, dass Sprachgeräte nicht zwischen ernst gemeintem Auftrag durch eine anwesende Person und eingeschmuggelte Fremd-Kommandos aus dem Fernsehlautsprecher unterscheiden können.)
Beispielsweise reagiert Siri auf meine Frage „Wieso beging van Gogh Selbstmord“ sehr fürsorglich und unpassend: „Falls du Selbstmordgedanken hast, möchtest du vielleicht mit jemandem von einem Suizidpräventionsprogramm sprechen. Alles klar, meine Websuche hat Folgendes ergeben: …“ Offenbar ist Siri mein rein sachlich-biografisches Interesse an Vincent van Goghs Ableben nicht bewusst.
Die Zukunft spricht
Die zwei Kompetenzen Sprache verstehen und Sprache ausgeben entheben den Computer seiner technischen Anmutung. Sie senken die psychologische Hürde, das Gerät im Alltag zu benutzen. Dadurch, dass sie mit uns auf eine Weise interagieren, die sich natürlich für uns anfühlt, kaschieren sie ihre technoide Kühle. Es mag uns anders erscheinen, aber beim Übergang in den Computer gilt der Befund von Heinz Buddemeier: „Aus der wahrnehmenden Intelligenz wird eine blinde Intelligenz, aus der fühlenden Intelligenz wird eine kalte Intelligenz, aus der sinngeleiteten Intelligenz wird eine dumme Intelligenz, und aus der verantwortenden Intelligenz wird eine gleichgültige Intelligenz.“
Auch wenn der Computer uns gefühlt entgegenkommt, indem er sich unseren Kommunikationsselbstverständlichkeiten (scheinbar) anpasst, so bleibt er doch ein gleichgültig-dummer Computer. Er kann nicht mehr, als ihm die innewohnende Mathematik gestattet. Kommandos, die er nicht kennt, kann er nicht ausführen. Anweisungen, die er nicht korrekt verarbeitet, führen für uns ins Leere. Wir als Nutzer sind daran gewöhnt, uns der Technik anzupassen. Das merkt man daran, wie Fragen an Google gestellt werden, eben nicht als Frage, sondern als Schlagwortfolge.
Wenn nun durch Voice-Geräte die Nutzer motiviert werden, sich an die Sprachverständniskompetenzen der Sprach-Erkennung anzupassen – und das wird zweifellos geschehen –, dann hat es Auswirkungen auf die Sprachnutzung allgemein. Denn im Gegensatz zu einer Texteingabe in die Google-Sucheingabe wird nun die selbe Kommunikationsform wie zwischen Menschen auch gegenüber Maschinen verwendet, nur eben in einer besonderen Ausprägung und einer anderen Erwartungshaltung. Vielleicht dauert es ja nicht mehr lange, bis die Menschen einander zurufen „Licht an!“, „Fenster zu!“ oder „Wie wird das Wetter heute?“ und dabei die gleiche Befolgungserwartung hegen.
Niemand weiß, was die Zukunft bringt. Vermutlich stehen wir erst am Anfang und haben noch viel mit der Sprachsteuerung vor uns. Vielleicht wird sie ja tatsächlich so omnipräsent und alltagsbestimmend, wie ich es unterstelle. Vielleicht wird die Sprachsteuerung auch nur ein weiterer, ergänzender Kanal zur Computer- oder Gerätesteuerung. Vielleicht gibt es in einigen Jahren keine Lichtschalter oder Radioknöpfe mehr, weil die Mehrheit mit den Füßen abgestimmt hat, dass sie das lieber per Stimmbefehl auslösen? Vielleicht kommt auch die nächste große Gadget-Revolution um die Ecke und drängt die Voice-Bedienung in eine Nische ab oder führt sie in eine ganz andere Richtung. Vielleicht wird auch irgendwo, zunächst für uns unbemerkt, Skynet oder die Matrix gegründet.
Im aktuellen Alltag erkenne ich für Voice-Interfaces wenig Mehrwert, aber das wird Gadget-Enthusiasten und Early Adopter nicht abhalten. Mich jedoch motiviert der Aufwand (Kosten, Installation, Wartung) nicht, damit alles wunschgemäß läuft, mir eine ins Haus zu holen. Licht und Radio ein- und ausschalten kann ich auch noch so. Für Webrecherchen oder klare Mini-Aufgaben habe ich ein Smartphone (mit Siri).
Doch wenn es den Voice-Plattformen gelingt – ob nun Alexa, Siri oder Google Now, vielleicht ja sogar Cortana –, im Massenmarkt Fuß zu fassen und in einem Großteil der Haushalte unterzukommen, befürchte ich massive Auswirkungen. Soziokulturell bin ich eher pessimistisch und erwarte das Nebeneinanderleben von Echokammern des jeweils eigenen Komforts. Wirtschaftlich wird der Handel sich stark umstellen müssen, und langfristig könnte sich der aktuelle eCommerce als Brückentechnologie erweisen und untergehen.
Das führt zu einer weiteren Konzentration von wirtschaftlicher Macht auf die drei Giganten Google, Amazon und Apple; Facebook fokussiert offenbar eher auf Virtuelle Realität als auf Sprach-Interface-Geräte. Selbst Microsoft könnte durch die Voice-Bedienung ins Straucheln geraten. Denn die Sprachsteuerung lässt die aktuelle Computernutzung in zwei Richtungen aufspalten: die bequemlichkeitsgetriebene Nutzung zuhause und im Privatbereich via Sprachsteuerung sowie die fokussierte Arbeit am Computer im Beruf. Mehr als zehn Prozent der Bevölkerung sind „mobile only“, nutzen also weder PC noch Laptop, sondern Smartphone und allenfalls Tablet. Das deutet darauf hin, dass wir unser Verständnis von Computer-Bedienung, -Einsatz und -Nutzung neu justieren müssen.
Denn was die Sprechgeräte inzwischen ganz gut können, ist menschliche Interaktion zu simulieren. Das gelingt zwar immer noch nicht annähernd so überzeugend wie beispielsweise „HAL“ in „2001 – Odyssee im Weltraum“. Aber immerhin wird das „uncanny valley“ überwunden (auch dank der nicht-anthropomorphen Erscheinung als Box). Werden wir daran gewöhnt, dass wir einfach Kommandos oder Fragen in den Raum rufen und entsprechend positives Feedback erhalten (Kommandos werden ausgeführt, Fragen beantwortet – und alles ohne Murren oder Vorbehalte), dann wird das auch Auswirkungen auf das verbale Miteinander zwischen den Menschen haben.
Hier der Text als digitale Vorlesung (MP3, 12 MB, 50 Minuten). Das ist zwar nicht die Original-Siri-Stimme, aber es klingt dennoch recht passabel.
 ein Kind der 70er • studierter Anglist/Amerikanist und Mediävist (M.A.) • wohnhaft in Berlin • Betreiber dieses Blogs zanjero.de • mehr über Alexanders Schaffen: www.axin.de ||
ein Kind der 70er • studierter Anglist/Amerikanist und Mediävist (M.A.) • wohnhaft in Berlin • Betreiber dieses Blogs zanjero.de • mehr über Alexanders Schaffen: www.axin.de ||